A path tracer with CUDA - prt 2
Table of Contents
In the last post I decide to follow the tile strategy. We want to process tiles of pixels in parallel. Each thread will handle a single tile by rendering all its pixels sequentially, then each tile will be indexed based on the thread’s grid position (CUDA):
// tile index
hermes::index2 tile_index(threadIdx.x + blockIdx.x * blockDim.x,
threadIdx.y + blockIdx.y * blockDim.y);
The first consequence here is that multiple tiles will dispute for the local memory in the streaming multi-processor. But let’s keep simple and go on :)
The pixel region \((x_0, y_0) \times (x_1, y_1)\) the tile tile_index covers can be easily computed as:
auto x0 = tile_index.i * tile_size;
auto x1 = x0 + tile_size;
auto y0 = tile_index.j * tile_size;
auto y1 = y0 + tile_size;
bounds2i tile_bounds({x0, y0}, {x1, y1});
// In the actual code, we need to take in consideration the offset of
// the super tile being rendered and of course, clamp to image borders
Now we render each pixel sequentially. Each pixel spawns multiple rays that will contribute with its final color. The rays leaving a particular pixel
are generated following randomly sampled points in the pixel area. The Sampler class takes the pixel position and generates the random points we need.
Each point is then passed to the Camera that computes the actual ray. Rays are instances of RayDifferential.
Each ray accumulates radiance (stored in the Spectrum class), and the combined radiance of all rays of a pixel will give its final color.
However, considering that real-world cameras
may register the final image into different types of film, we might want to apply filtering to our pixels as well. Thus, the idea is to have a class
FilmTile that perform those operations and is merged into the final Film later to form the final image. Here is the code:
auto film_tile = film.getFilmTile(tile_bounds);
// loop over pixels in tile
for(auto ij : tile_bounds) {
// initiate sampler to generate the pixel samples
sampler.startPixel(ij);
do {
// retrieve pixel samples
auto sample = sampler.sample(ij);
// compute camera ray
auto ray = camera.generateRayDifferential(sample);
// traces ray through the scene and computes its radiance
Spectrum L = ...
// register radiance into film tile
film_tile.addSample(sample, L);
} while(sampler.startNextSample());
}
// store final film tile radiances into final film
film.mergeFilmTile(film_tile);
Ok, there is a lot going on already and lots of classes that were not properly introduced. However I must recall that all that comes from PBRT. I’ll focus only on the main differences and details about my implementation.
Let’s start with the Sampler.
Sampling Pool⌗
Each rendering technique will require different amounts of samples per pixel. Each sample can be 1-dimensional or 2-dimensional. For example, we may need a sample for a 2D position in the pixel, and another 1D sample for time. We might even need arrays of samples as well. It really depends on the algorithm being used. However, each pixel will require the same amount of samples.
Since now we will be doing things on the GPU, the idea is to pre-allocate all necessary memory required by samples in the GPU global memory and let it just be recycled as pixels are rendered.
We could also avoid calculation during rendering by actually pre-generating samples before rendering. Regardless wether we store samples for all pixels or not, we still need to pre-allocate and manage memory for the samples. I’m thinking something along these lines:

The upper row in the figure represents the storage of a block of samples used by a single pixel. 1D and 2D samples are grouped in pairs that are called dimensional samples – nothing to do with 1D or 2D. The remaining stores the arrays of samples, which might not exist depending on the renderer.
Each block of samples (the entire upper row), in the figure called pixel sample, belongs to a pool item
in the SamplePool. The SamplePool manages all the memory used by the pixel samples from all tiles active in the GPU.
A pool item comprises a header
containing the sizes of the sample arrays stored in each pixel sample followed by an array of pixel sample blocks.
Each pool item can serve all the memory used by a tile for example.
Stratified Sampler⌗
I implemented the StratifiedSampler, which subdivides the sampling region (pixel area) with a regular grid and generates a
sample in each grid cell. A simple usage example goes like this:
// Here we define a 2x2 grid (4 samples), jittering and 3 sampling dimensions
StratifiedSampler sampler(hermes::size2(2, 2), true, 3);
// Allocate required memory for the pool
// Here considering a pool with just 1 item
hermes::UnifiedMemory mem(sampler.memorySize() * 1);
// Let the sampler know the memory it will use
sampler.setDataPtr(mem.ptr());
// Generate samples for the first item
sampler.startPixel({});
// Now can access the sample pool
auto pool = sampler.samplePool();
// Let's iterate by the grid and print the generated samples
for (auto ij : hermes::range2(hermes::size2(2, 2))) {
HERMES_LOG_VARIABLE( ij );
HERMES_LOG_VARIABLE( pool.get1DSample() );
HERMES_LOG_VARIABLE( pool.get2DSample() );
}
Here is the output:
> ij = Index[0, 0]
> pool.get1DSample() = 0.0206782
> pool.get2DSample() = Point2[0.00485516 0.396543]
> ij = Index[1, 0]
> pool.get1DSample() = 0.243698
> pool.get2DSample() = Point2[0.0563314 0.322041]
> ij = Index[0, 1]
> pool.get1DSample() = 0.0997249
> pool.get2DSample() = Point2[0.018033 0.359203]
> ij = Index[1, 1]
> pool.get1DSample() = 0.475705
> pool.get2DSample() = Point2[0.870503 0.137873]
In another test considering sample arrays:
// Defining a pool item containing 10 samples per pixel
// 3 dimensional samples, i.e. 3 pairs of 1d/2d samples per pixel sample
// 1 array of 1d samples containing 1 sample per pixel sample
// 2 arrays of 2d samples containing 1 sample per pixel sample
SamplePool::PoolDescriptor descriptor = {
.samples_per_pixel = 10,
.dimensions = 3,
.array1_sizes = {1},
.array2_sizes = {2, 1}
};
// Generate samples
...
// Dump memory
SamplePool::dumpMemory(pool, pool_size);
The screenshot bellow shows the beginning of the pixel sample block:
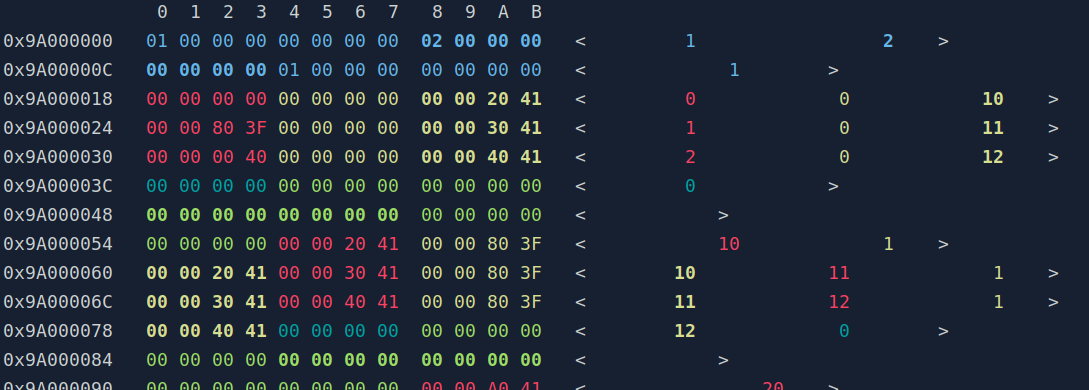
First we find the header containing the array sizes 1, 2, and 1. Then follows the list of pixel samples, being only 2 visible in the screenshot. The pixel sample starts with 3 pairs of 1 1D sample and 1 2D sample, with values [0, (0, 10)], [1, (0, 11)] and [2, (0, 12)] in the screenshot. In the remaining of the pixel sample lie the arrays (56 bytes).
Notes⌗
- Since pixels inside a thread are rendered sequentially, we could store samples just for 1 pixel per tile. Then every time the next pixel of that tile is rendered, the samples are re-calculated using the same memory.
The next post talks about how we deal with objects and data structures.